
Apache Lucene is a high-performance, full-featured text search engine library. Here's a simple example how to use Lucene for indexing and searching
To run this example you need to download lucene-3.0.2.zip from http://www.apache.org/dyn/closer.cgi/lucene/java
If you need more information about Lucene go to http://lucene.apache.org/java/docs/index.html
To use Lucene, an application should:
1. Create Documents by adding Fields;
2. Create an IndexWriter and add documents to it with addDocument();
3. Call QueryParser.parse() to build a query from a string; and
4. Create an IndexSearcher and pass the query to its search() method.
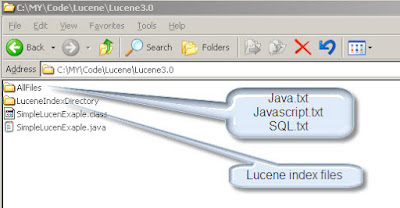
Lets create a directory called "AllFiles" that contains text files that we are going to index. We have a directory called "LuceneIndexDirectory". This will hold the index that lucene creates.
Now Lets create few files in "AllFiles" folder which will contain few key words which we will search. Here are the files below.
Look at sample folder structure
Java.txt
String
Object
ArrayList
Hashtable
Integer
Random
SQL.txt
Select
Group by
Where
From
random
Javascript.txt
object
Var
function
random
Now lets look at a simple example SimpleLucenExaple.java
First we will create index of all files in our "LuceneIndexDirectory" folder using createIndex(); method, then we will try to search few key words in our files using searchIndex(""); method
To know about this example lets look at Lucene 3.0.1 API
Assuming you have set lucene-core-3.0.2.jar, lucene-demos-3.0.2.jar in classpath.
/*
SimpleLucenExaple.java
*/
import java.io.File;
import java.io.FileReader;
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
public class SimpleLucenExaple {
String allFiles = "AllFiles";
String luceneIndexDirectory = "LuceneIndexDirectory";
IndexSearcher searcher = null; //the searcher used to open/search the index
Query query = null; //the Query created by the QueryParser
TopDocs hits = null; //the search results
public void searchIndex(String searchString)
{
System.out.println("Searching.... '" + searchString + "'");
try
{
IndexReader reader = IndexReader.open(FSDirectory.open(new File(luceneIndexDirectory)), true);
searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30 );//construct our usual analyzer
QueryParser qp = new QueryParser(Version.LUCENE_30 , "contents", analyzer);
query = qp.parse(searchString); //parse the query and construct the Query object
hits = searcher.search(query, 100); // run the query
if (hits.totalHits == 0)
{
System.out.println("No data found.");
}
else
{
for (int i = 0; i < hits.totalHits; i++)
{
Document doc = searcher.doc(hits.scoreDocs[i].doc); //get the next document
String url = doc.get("path"); //get its path field
System.out.println("Found in :: "+url); }
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
public void createIndex()
{
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
try
{
// Store the index in file
Directory directory = new SimpleFSDirectory(new File(luceneIndexDirectory));
IndexWriter iwriter = new IndexWriter(directory, analyzer, true,MaxFieldLength.UNLIMITED);
File dir = new File(allFiles);
File[] files = dir.listFiles();
for (File file : files)
{
System.out.println(file.getPath());
Document doc = new Document();
doc.add(new Field("path", file.getPath(), Field.Store.YES, Field.Index.ANALYZED ));
Reader reader = new FileReader(file.getCanonicalPath());
doc.add(new Field("contents", reader)); iwriter.addDocument(doc);
}
iwriter.optimize(); iwriter.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
public static void main(String[] args)
{
SimpleLucenExaple obj = new SimpleLucenExaple();
System.out.println("************Creating Index************");
obj.createIndex();
System.out.println("************Searching************");
obj.searchIndex("Object AND Random");
obj.searchIndex("Object");
obj.searchIndex("random OR Object");
obj.searchIndex("ObjectRandom");
obj.searchIndex("Function");
obj.searchIndex("Group");
obj.searchIndex("form where");
}
}
Console output
************Creating Index************
AllFiles\Java.txt
AllFiles\Javascript.txt
AllFiles\SQL.txt
************Searching************
Searching.... 'Object AND Random'
Found in :: AllFiles\Javascript.txt
Found in :: AllFiles\Java.txt
Searching.... 'Object'
Found in :: AllFiles\Javascript.txt
Found in :: AllFiles\Java.txt
Searching.... 'random OR Object'
Found in :: AllFiles\Javascript.txt
Found in :: AllFiles\Java.txt
Found in :: AllFiles\SQL.txt
Searching.... 'ObjectRandom'
No data found.
Searching.... 'Function'
Found in :: AllFiles\Javascript.txt
Searching.... 'form where'
Found in :: AllFiles\SQL.txt
To know about this example lets look at Lucene 3.0.1 API
Any feedback/comments? Do write me, I would love to answer it.
To run this example you need to download lucene-3.0.2.zip from http://www.apache.org/dyn/closer.cgi/lucene/java
If you need more information about Lucene go to http://lucene.apache.org/java/docs/index.html
To use Lucene, an application should:
1. Create Documents by adding Fields;
2. Create an IndexWriter and add documents to it with addDocument();
3. Call QueryParser.parse() to build a query from a string; and
4. Create an IndexSearcher and pass the query to its search() method.
Lets create a directory called "AllFiles" that contains text files that we are going to index. We have a directory called "LuceneIndexDirectory". This will hold the index that lucene creates.
Now Lets create few files in "AllFiles" folder which will contain few key words which we will search. Here are the files below.
Look at sample folder structure

Java.txt
String
Object
ArrayList
Hashtable
Integer
Random
SQL.txt
Select
Group by
Where
From
random
Javascript.txt
object
Var
function
random
Now lets look at a simple example SimpleLucenExaple.java
First we will create index of all files in our "LuceneIndexDirectory" folder using createIndex(); method, then we will try to search few key words in our files using searchIndex("
To know about this example lets look at Lucene 3.0.1 API
Assuming you have set lucene-core-3.0.2.jar, lucene-demos-3.0.2.jar in classpath.
/*
SimpleLucenExaple.java
*/
import java.io.File;
import java.io.FileReader;
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
public class SimpleLucenExaple {
String allFiles = "AllFiles";
String luceneIndexDirectory = "LuceneIndexDirectory";
IndexSearcher searcher = null; //the searcher used to open/search the index
Query query = null; //the Query created by the QueryParser
TopDocs hits = null; //the search results
public void searchIndex(String searchString)
{
System.out.println("Searching.... '" + searchString + "'");
try
{
IndexReader reader = IndexReader.open(FSDirectory.open(new File(luceneIndexDirectory)), true);
searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30 );//construct our usual analyzer
QueryParser qp = new QueryParser(Version.LUCENE_30 , "contents", analyzer);
query = qp.parse(searchString); //parse the query and construct the Query object
hits = searcher.search(query, 100); // run the query
if (hits.totalHits == 0)
{
System.out.println("No data found.");
}
else
{
for (int i = 0; i < hits.totalHits; i++)
************Creating Index************
AllFiles\Java.txt
AllFiles\Javascript.txt
AllFiles\SQL.txt
************Searching************
Searching.... 'Object AND Random'
Found in :: AllFiles\Javascript.txt
Found in :: AllFiles\Java.txt
Searching.... 'Object'
Found in :: AllFiles\Javascript.txt
Found in :: AllFiles\Java.txt
Searching.... 'random OR Object'
Found in :: AllFiles\Javascript.txt
Found in :: AllFiles\Java.txt
Found in :: AllFiles\SQL.txt
Searching.... 'ObjectRandom'
No data found.
Searching.... 'Function'
Found in :: AllFiles\Javascript.txt
Searching.... 'form where'
Found in :: AllFiles\SQL.txt
To know about this example lets look at Lucene 3.0.1 API
Any feedback/comments? Do write me, I would love to answer it.